近日,国际顶级会议ACM Multimedia 2024在澳大利亚墨尔本举办,由朱艾春和董冠男老师指导的我院2022级研究生张旭同学(第一作者)的长文 “TVPR: Text-to-Video Person Retrieval and a New Benchmark”被大会录用。ACM Multimedia是计算机学科多媒体领域的顶级国际会议,也是中国计算机学会(CCF)推荐的该领域唯一的A类国际学术会议。ACM Multimedia 2024共有4385篇投稿进入审稿阶段,经过Rebuttal后,最终有1149篇论文(26.20%)被录用。

图1:图片遮挡以及动作信息缺失情况示例
该论文提出了一个文本-视频行人检索(TVPR)新任务以及一个新数据集,并在此基础上提出了一种多元特征引导的片段化学习策略(Multielement Feature Guided Fragments Learning strategy,MFGF)。现有的大多数基于文本的人物检索方法都侧重于文本-图像的人物检索。然而,由于孤立帧提供的动态信息不足,当人物被遮挡时(如图1所示),检索性能会受到极大的影响。

图2:TVPReid数据集高频词云与行人视频示例
由于目前没有包含自然语言描述的行人视频数据集或基准,该研究团队耗费半年时间构建了一个大规模文本-视频行人检索数据集(Text-to-Video Person Re-identification dataset,TVPReid)。该数据集包含6559个行人视频,每个行人视频有两段文本描述。据悉,该团队将于近期公开发布该数据集。
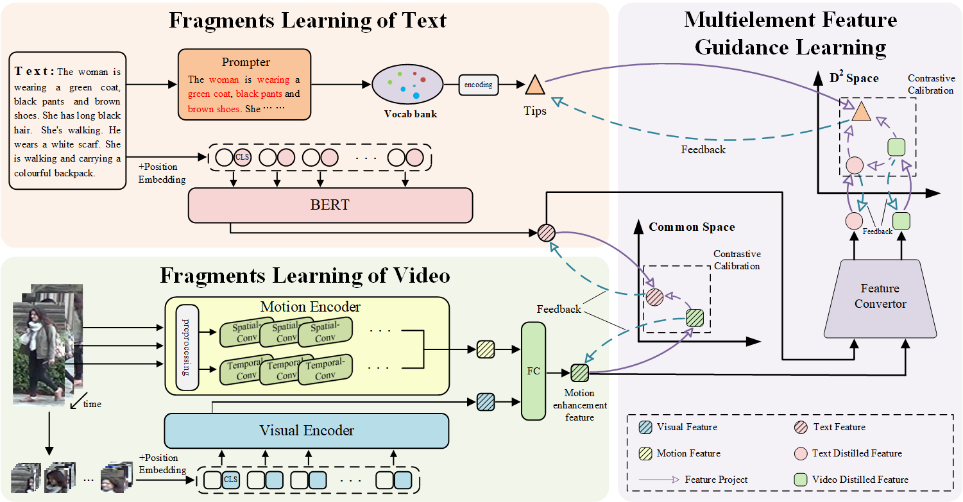
图3:模型结构图
针对文本-视频行人检索任务,该论文提出了一种多元特征引导的片段化学习 (MFGF) 策略,该策略利用跨模态文本-视频表征来提供强大的文本-视觉和文本-运动匹配信息,以应对不确定的遮挡冲突和可变运动细节。该模型利用ViT和S3D联合提取行人视频的特征,增强视频特征中的动作信息,同时利用BERT编码文本描述,提取文本特征。此外,MFGF为文本和视频特征协作学习建立了两个潜在的跨模态空间,进一步缩小文本和视频之间的跨模态语义鸿沟,提升模型对文本-视频跨模态信息中语义共性的理解,进而提高了检索精度。
作者:朱艾春(计算机与信息工程学院(人工智能学院))
审核:高辉庆、万夕里
